

MLflow is probably the most popular tool for model registry and experiment tracking out there. MLFlow is open source and integrates with a lot of platforms and tools.
Due to its extensive support and a lot of options, getting started with MLflow may feel overwhelming. In this article, we will get back to the basics, and will review 3 most important, in my opinion, classes in MLFlow:
mlflow.entities.Experiment
mlflow.entities.Run
mlflow.entities.model_registry.ModelVersion
We will see how those entities get created, how you can retrieve them, and how they change based on different input parameters. In this article, the Databricks version of MLflow is used, so it contains some Databricks-specific information. However, the idea is generalizable to any MLflow instance.
Understanding how these 3 classes work will help you how to go from reiterating over multiple versions of the model to model selection and registering the model.
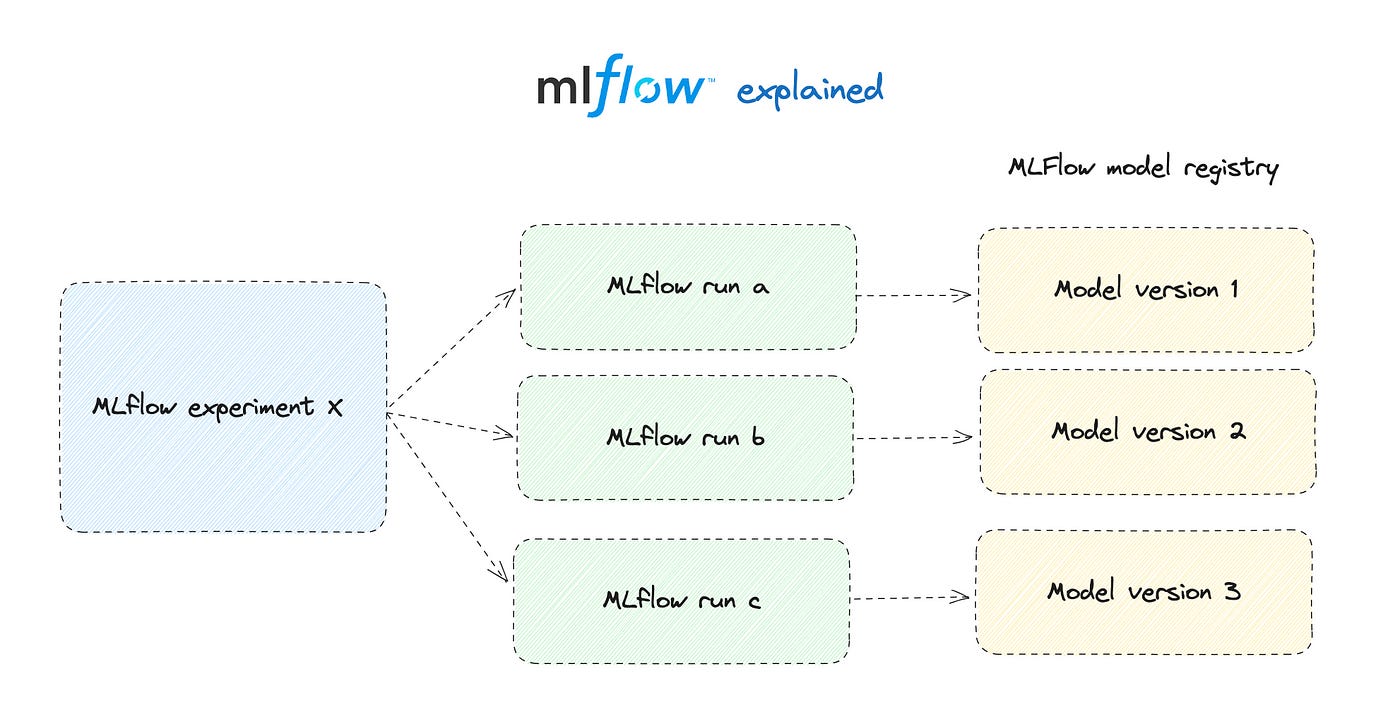
MLflow Experiment
Experiments in MLflow are the main unit of organization for ML model training runs. All MLflow runs belong to an experiment.
Create an MLflow experiment
MLflow Experiment can be created by using mlflow.create_experiment or mlflow.set_experiment commands. The last one will activate the existing experiment by name or will create a new one if such an experiment does not exist yet.
It is possible to add tags to your experiment by passing it as a parameter to mlflow.create_experiment command, or, if the experiment already exists, using mlflow.set_experiment_tags command after the experiment got activated.
import mlflow
mlflow.set_experiment(experiment_name='/Shared/demo')
mlflow.set_experiment_tags({"repository_name": "demo"})The above commands will result in the creation of an instance of mlflow.entities.Experiment class with the following attributes:

All the tags except repository_name are created by MLFlow by default.
Search for an MLflow experiment
The MLflow experiment created above can be now found by name or by tag:
# search experiment by name
mlflow.search_experiments(filter_string="name='/Shared/demo'")
# search experiment by tag
mlflow.search_experiments(filter_string="tags.repository_name='demo'")It is also possible to search for experiments by last_update_time or creation time.
MLflow Run
An MLflow run is related to a single execution of ML model training code, under an MLflow run a lot of things can be logged: params, metrics, and artifacts of different formats.
Logging & loading attributes and artifacts of an MLFlow run
MLflow run can be created by running mlflow.start_run command. The command is used within “with” block. If you do not use it, you would have to run mlflow.end_run command.
with mlflow.start_run(
run_name="demo-run",
tags={"git_sha": "51v63531711eaa139"},
description="demo run",
) as run:
mlflow.log_params({"type": "demo"})
mlflow.log_metrics({"metric1": 1.0,
"metric2": 2.0})The code above will result in the creation of an instance of mlflow.entities.Run class. We logged some parameters and metrics and added a tag: git sha, which is very useful. It is possible to search for it using the following commands:
run_id = mlflow.search_runs(
experiment_names=['/Shared/demo'],
filter_string="tags.git_sha='51v63531711eaa139'").run_id[0]
mlflow.get_run(run_id=f'{run_id}').to_dictionary()The retrieved MLflow run can be visualized in the following way (some lower-level information is skipped in the visualization):

Various run artifacts can also be logged and retrieved later. The cheat sheet shows how attributes (params and metrics) and artifacts can be loaded into memory from the MLflow tracking server.

For certain model flavors, auto-logging can be done by running mlflow.<model_flavor>.autolog command, which will store metrics and parameters for ML models without explicitly coding them.
All artifacts can be downloaded using mlflow.artifacts.download_artifacts command.
Logging and registering an ML model
To register a model, you need to log it first by running mlflow.<model_flavor>.log_model command. The number of supported model flavors is growing, but, in general, any Python class can be logged if wrapped using mlflow.pyfunc.PythonModel. See, for example, how we did it in this article: https://marvelousmlops.substack.com/p/going-serverless-with-databricks.
In our demo example, we are logging a sklearn model (not even trained), just to understand how logging and registering a model works in MLflow.
from sklearn.linear_model import LogisticRegression
with mlflow.start_run(
run_name="demo-run",
tags={"git_sha": "51v63531711eaa139"},
description="demo run",
) as run:
model = LogisticRegression()
mlflow.sklearn.log_model(model, artifact_path="model")When the model is logged, it is not yet registered in MLflow Model Registry (unless “registered_model_name” argument is passed). The following command must be run:
mlflow.register_model(model_uri=f"runs:/5f871c4f04e04dc295f5c77/model",
name='demo-model',
tags={"git_sha": "51v63531711eaa139"})This code creates an entity of mlflow.entities.model_registry.ModelVersion class, and it looks like this:

A model can be loaded into memory using mlflow.<model_flavor>.load_model command. It is possible to search for a model in the following way:
mlflow.search_model_versions(
filter_string="name='demo-model' and tag.git_sha='51v63531711eaa139'")It is useful to tag your model with information about the run to make it even easier to search for. See, for example, https://www.linkedin.com/feed/update/urn:li:activity:7093134432722644992
Final thoughts
MLflow is a great tool for experiment tracking, but it is hard to find good documentation on how to start with it and use it without getting lost in many functions. I hope I made it easier for other developers that are using MLflow.