
Model serving architectures on Databricks

Many different components are required to bring machine learning models to production. I believe that machine learning teams should aim to simplify the architecture and minimize the amount of tools they use.
Databricks provides a lot of features and allows to do MLOPs end-to-end, including model serving. Regarding model serving, Databricks has two interesting features: Model Serving and Feature serving. Note that Unity Catalog is required for serving.
After trying these features in different scenarios, I can say that using them can significantly simplify your pipelines. Moreover, data scientists can easily deploy models themselves without the help of machine learning engineers.

In this article, we discuss the following architectures:
serving batch prediction
on-demand synchronous serving (with batch and real-time features)
on-demand asynchronous tasks
The first two were inspired by the blog by Roy van Santen from Xebia: https://xebia.com/blog/ml-serving-architectures/. Read the article to deep dive into the pros & cons of various architectures.
Serving batch predictions
Serving batch predictions is probably one of the most popular and underestimated types of machine learning model deployment. Predictions are computed in advance using a batch process, stored in an SQL or in-memory database, and retrieved at request.
This architecture is very popular in the case of personal recommendation with low latency requirements. For example, an e-commerce store may recommend products to customers on various pages of the website.

We advise using Databricks' Feature Serving in this scenario. Pre-computed features are stored in a Feature Table. An Online table (read-only copy of the Feature Table designed for low latency) and FeatureSpec (user-defined set of features and functions) are used behind the Feature Serving endpoint.
To understand how to get started with Feature Serving, check out our earlier article.
On-demand synchronous serving
In the case of synchronous serving, predictions are computed the moment a user requests it. To compute the predictions, a model artifact is required. Model artifact is created in a batch fashion as the result of a model training pipeline.
All input features required must be available for the model to compute the predictions. Input features can be passed with a request, or retrieved from a Feature Store (those features can be computed in a batch or streaming fashion, depending on your needs), or both.
On-demand synchronous serving can be used for fraud detection, more complex recommendations, and many other use cases.
Databricks Model Serving can be very useful here. Model features (batch or real-time) are stored in a Feature Table. An Online table (read-only copy of the Feature Table designed for low latency) and a mlflow model are used behind the Model Serving endpoint. We will write about it in detail in the follow-up articles.
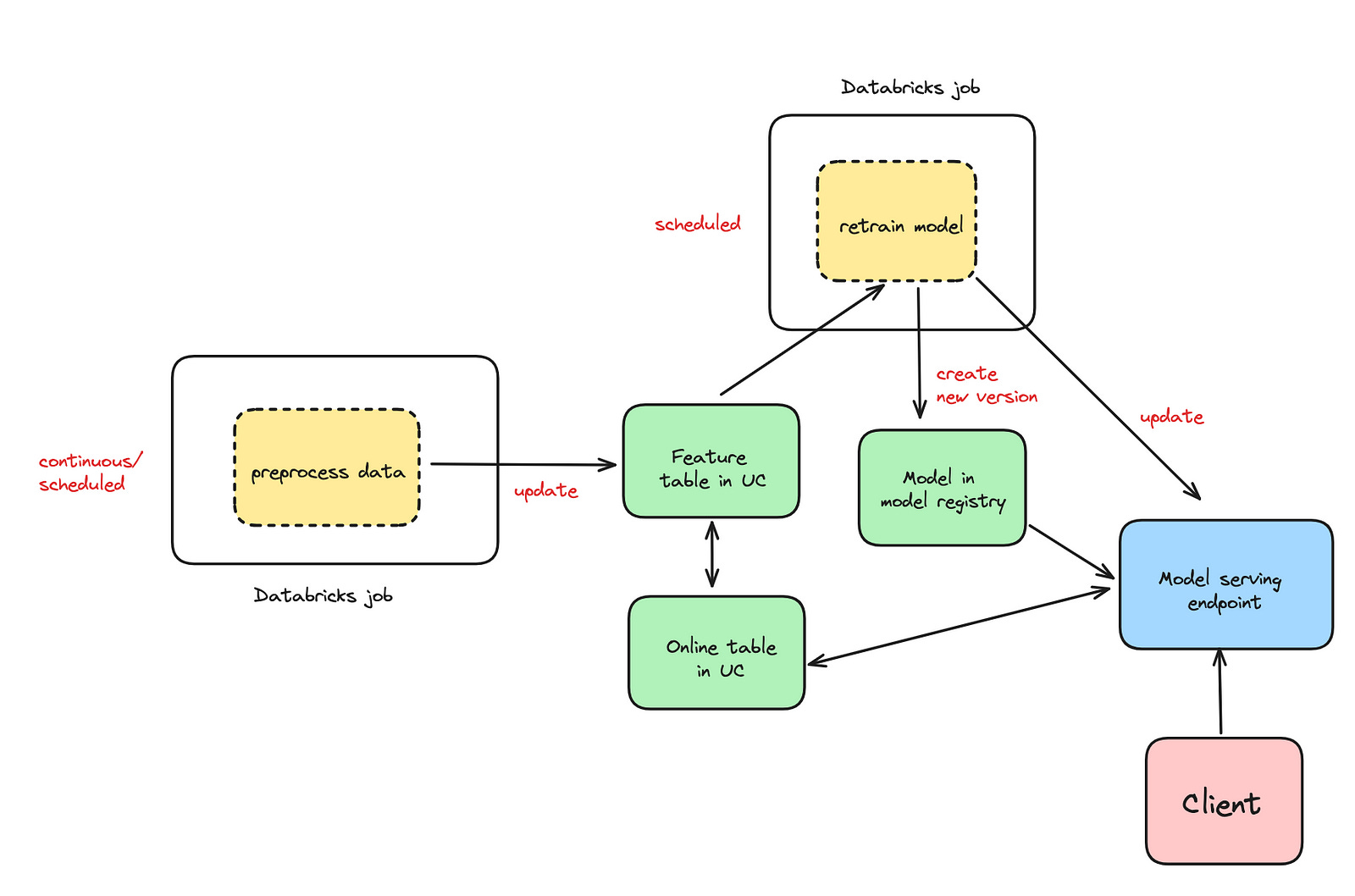
When there is no feature lookup required at the moment of request, and all features are available as part of the request, architecture is simpler. We just need a model in the model registry behind a Model Serving endpoint. Check out our previous articles on the topic: part 1, part 2.
On-demand asynchronous tasks
On-demand asynchronous tasks can be very useful when a user needs to trigger a long-running task (that takes from several minutes to hours) and retrieve the results of the task later. Important to note that the task requires users' input to run, otherwise we could have just scheduled the whole process.
I have seen several use cases that require this architecture in my career. It was mainly related to optimization tasks: calculating the optimal route based on the location and calculating the optimal shelf layout in the store based on the shelf length and product.
Business users can pass parameters via a dashboard, and then view it later when calculation is done.
This can be achieved using Celery and FastAPI. See, for example, this article: with Celery and FastAPI, see, for example, this article: https://testdriven.io/blog/fastapi-and-celery/.
With Databricks, we can significantly simplify the setup.
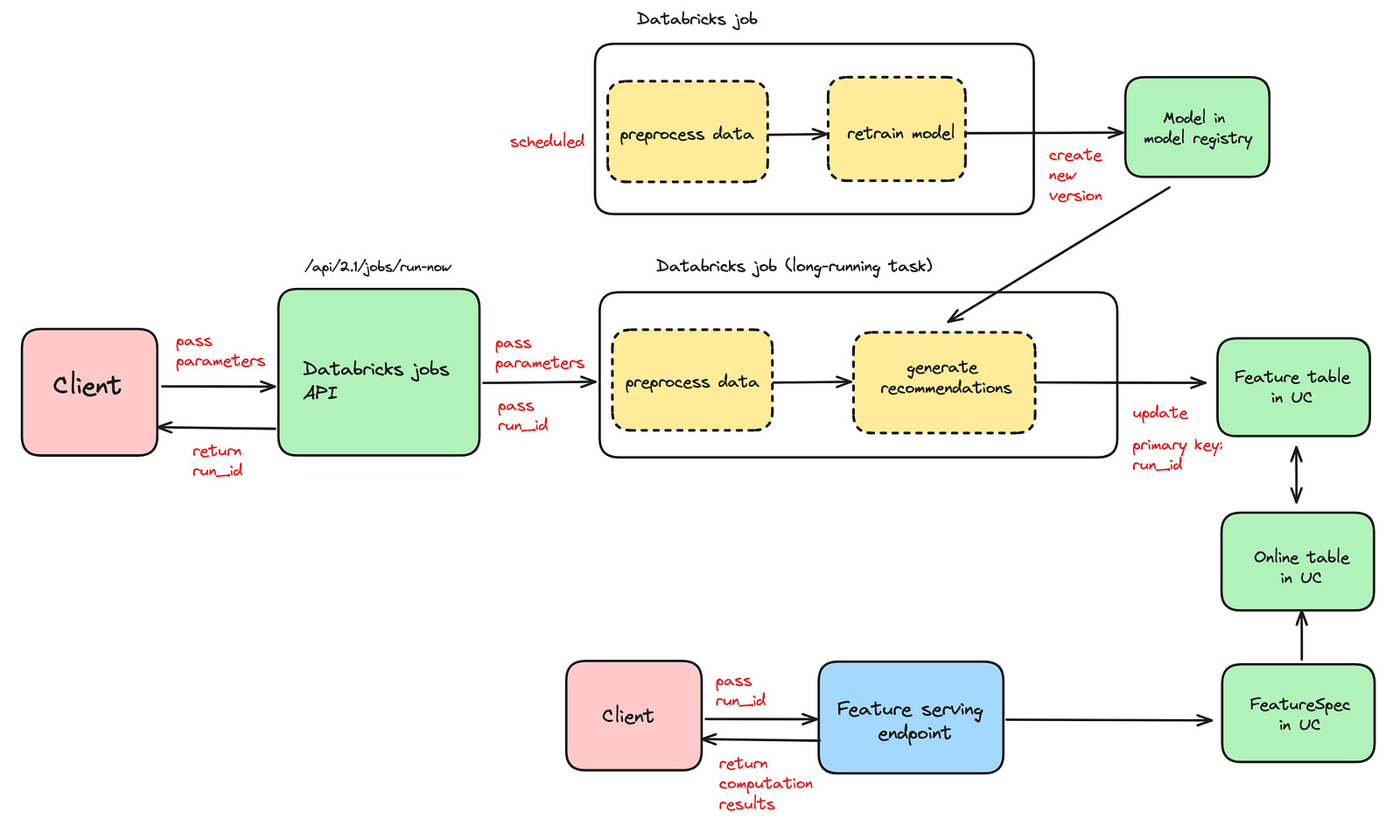
The client simply calls Databricks job API to trigger the job run and passes Python parameters to the Databricks job. Databricks run_id is also passed as a Python parameter {{job.run_id}}. See more information on parameter value references here: https://docs.databricks.com/en/workflows/jobs/parameter-value-references.html
Parameters provided by the client, along with the model from the model registry, are used to generate recommendations. These recommendations are stored in the Feature Table, where run_id is the primary key.
An Online table (read-only copy of the Feature Table designed for low latency) and FeatureSpec (user-defined set of features and functions) are used behind the Feature Serving endpoint.
The clients can now retrieve predictions by calling the Feature Serving endpoint and providing run_id (which the client gets as the response when The Databricks job API is called).
Conclusions & follow-up
Databricks now supports a wide range of machine learning model deployment architectures. Even though they come with some limitations (for example, you have limited influence on the payload structure), it significantly simplifies the deployment.
In the follow-up articles, we will deep dive into the on-demand synchronous serving use case with batch/real-time features, and explore the deployment of LLM applications with Databricks.