

In the previous article, we introduced MLOps maturity assessment. That assessment can also be interpreted as MLOps standards, a checklist for ML models before they go to production. It is highly recommended to include these standards as part of the “definition of done” in Agile methodology.
In general, data scientists/ML engineers should be able to invent their own ways to follow the standards, but when it comes to large corporates, doing it on your own can be very slow and inefficient. That’s why we suggest having a “golden path”, a framework for ML model deployment that follows MLOps standards by default. But where should we start? The first step is discovering what components of the basic MLOps toolbelt you have in-house. In an enterprise, it is much harder to incorporate a new tool into the systems than use an existing one, therefore it is always a good idea to start with what you already have.
MLOps toolbelt
Those components are needed for the minimal MLOps set up in order to deploy ML models reliably to production:
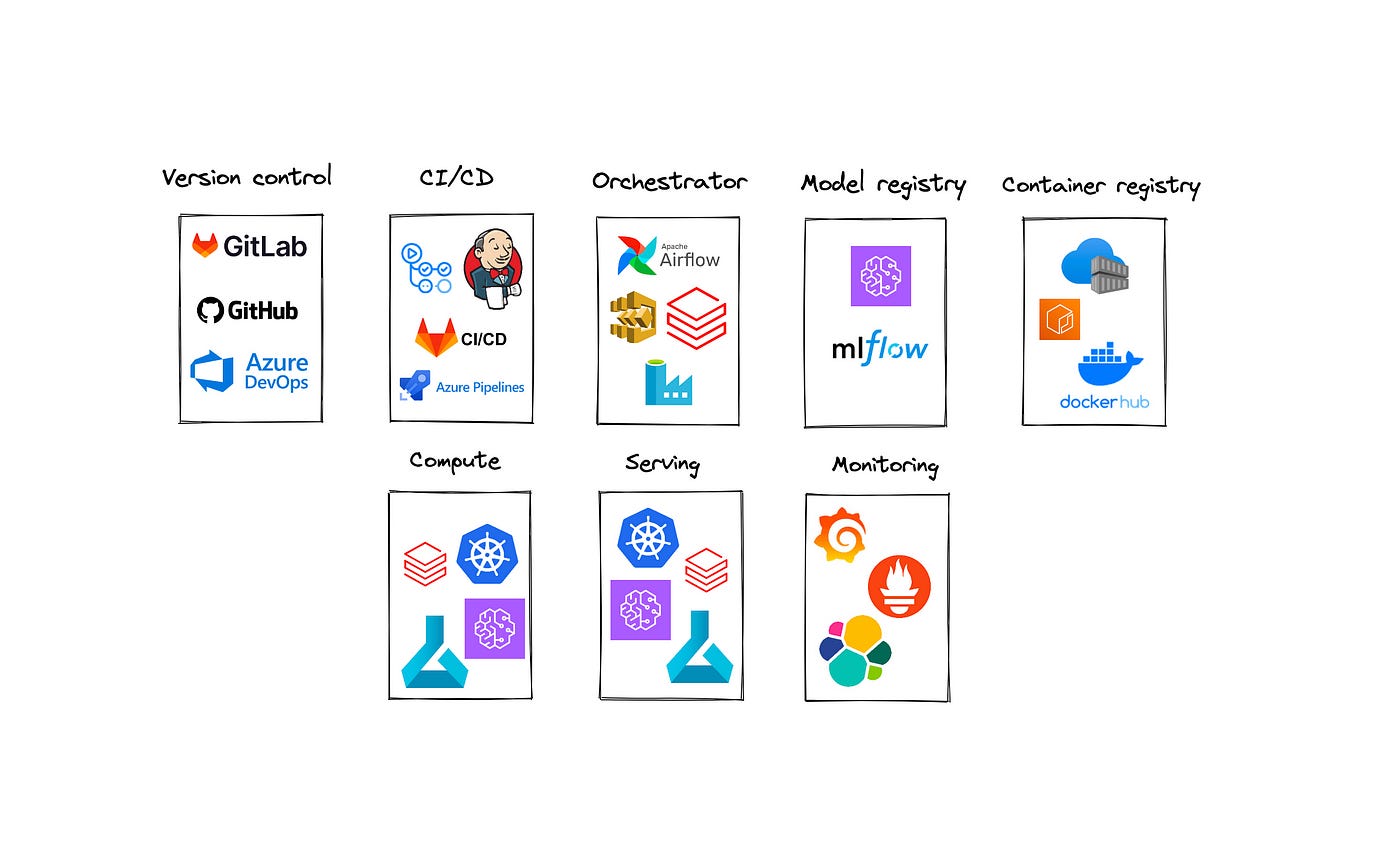
Version control
Version control is crucial for the traceability and reproducibility of an ML model deployment or run. Without using a version control system, it is difficult to find out what exact code version was responsible for certain runs or errors that you might have in production. Version control systems also provide useful features such as branch protection rules. This ensures code quality by allowing merge, only after getting approval from code reviewers and successful CI pipeline runs.
In a corporate organization there is already a version control system in place (sometimes even more than one), and choosing the version control system that is already used by most other departments is important to simplify possible integrations in the future. The diagram above shows some examples of version control systems, such as GitHub, Azure DevOps, and GitLab.
2. CI/CD
In MLOps, CI/CD pipelines play a key role. It’s essential that CI/CD pipelines containing automated tests are triggered upon pull request creation. Additionally, deployment to production should only occur through the CD pipeline. It’s important to note that individual developers should not be granted permission to deploy ML model code to production.
Most version control systems provide built-in CI/CD solutions, for example, GitHub Actions, GitLab CI/CD, and Azure Pipelines. Other CI/CD solutions like Jenkins, and CircleCI integrate with the most popular version control systems. In a corporate environment, it is important to understand what CI/CD solutions are mostly used and choose the same to simplify integration.
3. Workflow orchestration
Typical ML projects require Workflow orchestration to manage the complex dependencies between different tasks, such as data preprocessing, feature engineering, ML model training (which can also be parallel tasks, when the model is trained per category), ML model prediction, ML model deployment in case of API.
Tools like Airflow, Databricks workflows, and AWS Step Functions can be used for workflow orchestration. If your organization does not provide a workflow orchestration tool as a service, it can be a lot of work to support such a tool on your own (mainly because of security patching). Therefore it might be wise to choose managed services, there are always some options available if your organization uses a cloud provider.
4. Model & Container registry
Another crucial aspect of MLOps is the model registry. This includes storing and versioning trained ML model artifacts, together with additional metadata (hyperparameters, performance metrics, etc.). MLflow is by far the most popular model registry tool out there.
Next to storing machine learning models, it may be necessary to store docker images as part of your MLOps setup. For example, you might use Kubernetes to run model training jobs or to serve models, you might need to provide custom docker images to AWS Sagemaker / AzureML, or you might use docker images to run unit/integration tests in a CI/CD system. All these scenarios require a tool to store your images. Very likely your organization already has a container registry of choice, just go for it!
5. Model training & Serving
The model needs to be trained somewhere, and there are multiple options depending on the setup you have. If your organization is on-premise, you will most likely have to go with Kubernetes. If you are on a cloud provider, there are multiple choices out there: Azure ML on Azure, Sagemaker on AWS, and Vertex AI on GCP. Tools like Databricks are available in multiple cloud providers, which can also be one of the most convenient options. The most important thing to keep in mind is that it should be possible to run a machine-learning model script without changes in different environments (development, acceptance, production, etc.).
When talking about model serving, Azure ML, Sagemaker, Vertex AI, and Databricks provide a managed solution that simplifies model deployment significantly. Still, a lot of organizations (especially those with high Kubernetes adoption) prefer to deploy ML models on Kubernetes. It can also be handy when other services (for example, a website) are running on the same Kubernetes cluster and you have low latency requirements.
6. Monitoring
Monitoring is an essential piece of an MLOps setup. Monitoring in ML systems goes beyond what is needed for monitoring regular software applications. The distinction lies in the fact that the model predictions can fail even if all typical health metrics appear to be in good condition. Model performance should be checked regularly to prevent unexpected predictions from being consumed by end users.
Tools like Azure ML, and Sagemaker provide features to monitor model drift. However, it’s ideal to have all metrics in one place and use the monitoring systems already adopted by other teams. ELK stack, Splunk, and Prometheus+Grafana setup can be options that you might already have.
What next?
We are not believers in buying end-to-end “MLOps tools” claiming to do all of it. In the end, it is all about how you use it and how you integrate it with all other systems, not to mention complicated sourcing and security discussions that you will need to have before buying any tools. We think that leveraging existing tools within the organization can get you faster towards being MLOps mature.
After having defined what tools you need to do MLOps within your organization, it is important to figure out how to tie these pieces together: how the code stored in version control can be triggered by CD pipelines to run on a chosen compute system and get deployed on a chosen serving environment, and how all this can be monitored.
Last but not least, the goal is not to create a complex architecture, it is to create a simple design with all necessary functionality.

In the next articles, we will discuss how we created our MLOps solution design with the tools we have, it will be a lot around Github actions and Databricks. Stay tuned!
Hi everyone,
Thanks for this info, it was really useful!