Traceability & Reproducibility

In the context of MLOps, traceability is the ability to trace the history of data, code for training and prediction, model artifacts, environment used in development and deployment. Reproducibility is the ability to reproduce the same results by tracking the history of data and code version.
Traceability allows us to debug the code easily when there are unexpected results seen in production. Reproducibility allows us to generate the same model with the same data and code version, by guaranteeing the consistency, thus rolling back to the previous model version is always easy. Both are key aspects of MLOps that ensure transparency and reliability of ML models.
In our MLOps maturity assessment, we also include traceability among our checklists. As we describe there, what we want to implement is the following:
For any given machine learning model run/deployment in any environment it is possible to look up unambiguously:
corresponding code/commit on git
infrastructure used for training and serving
environment used for training and serving
ML model artifacts
what data was used to train the model.
Our motivation: Things can go wrong
Machine learning models running on production can fail in different ways. They can provide wrong predictions, produce biased results. Often, those unexpected behaviours are difficult to detect, especially if the operation seems to be running successfully. In case of an incident, traceability allows us to identify the root cause of the problem and take quick action. We can easily find which code version is responsible for training and prediction, which data is used.
Example failures:
On the grocery web shop, the suggested products section might be recommending cat food for customers who purchased dog toys.
Demand forecast algorithms might calculate high demand for ice cream during a winter storm, resulting in empty shelves for winter essentials like bread and milk.
Personalised offers recommend meat products to all customers, also for those who has been vegan for years and never purchased meat or dairy.
Our solution: Traceability by design
In our last article we mentioned the toolkit for MLOps with necessary components:
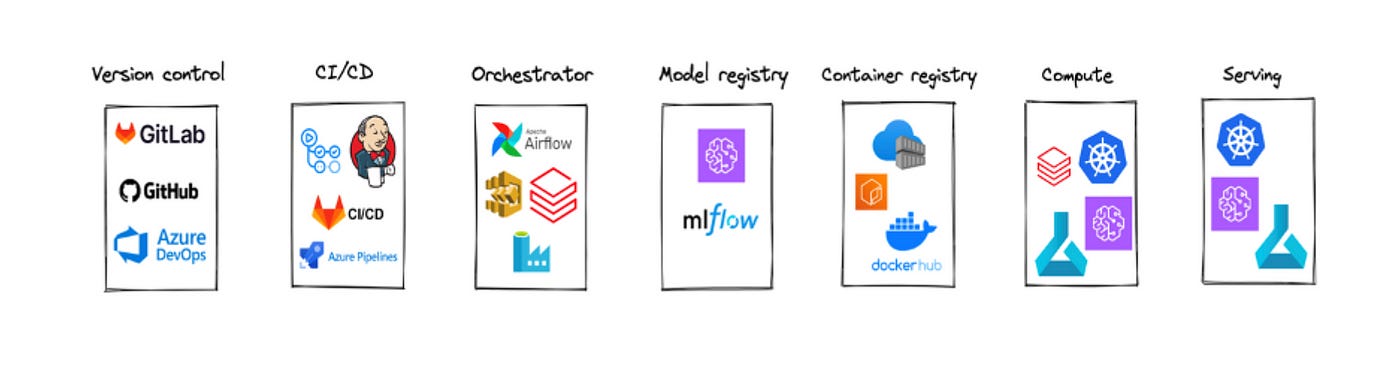
Our solution landscape consists of GitHub (version control), GitHub Actions (CI/CD), Databricks Workflows (Orchestrator), MLflow (Model registry), ACR (container registry), Databricks workflow (compute), AKS (serving).
Solution design for real-time inference model:
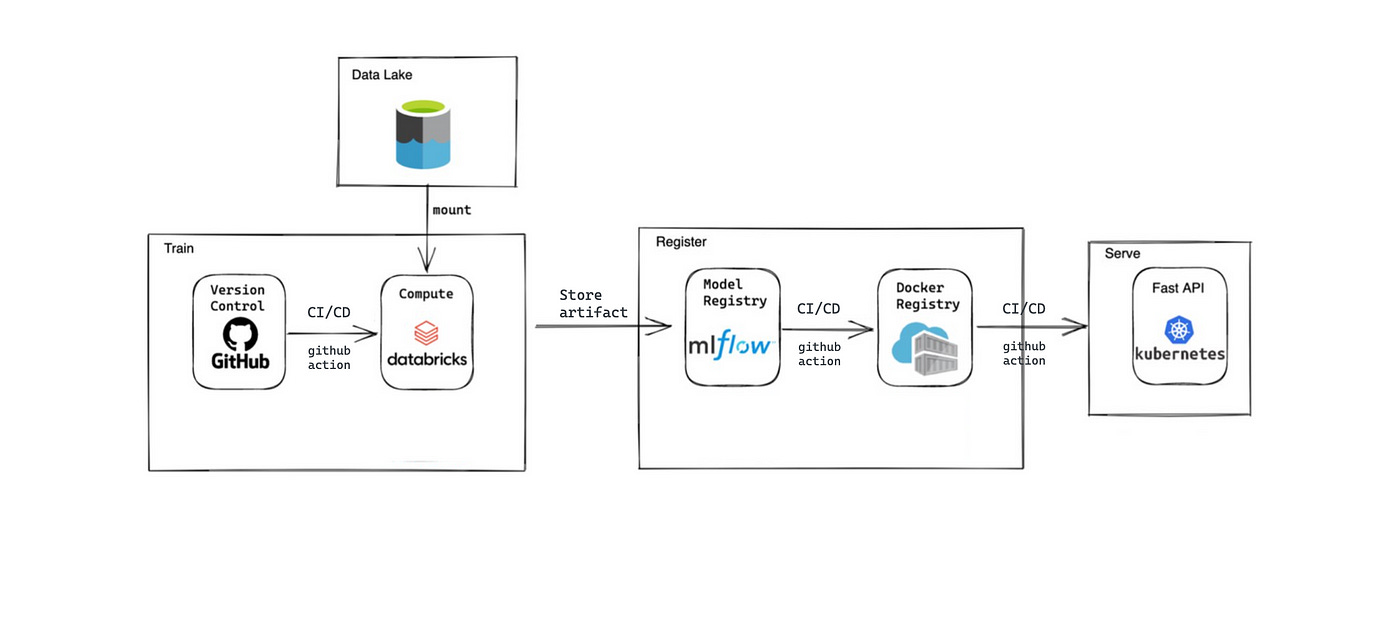
Below, our solution is defined step by step. Traceability components at each step are described in the next section.
1. We use GitHub as our code base where we create and release new versions.
2. CI pipelines are triggered automatically when there is a PR to main branches. CD pipeline releases a new version, creates/updates Databricks job for training and/or prediction. Azure Blob Storage is our data lake, and mounted to Databricks workspace.
3. After training, model artifacts are saved in mlflow, and a new model version is registered.
4. Github action CD pipeline retrieves the model artifact from mlflow, and creates a docker image with it. The docker image is pushed to Azure Container Registry.
5. The last step is to deploy the container from ACR to AKS to run our application.
Traceability on real-time inference model:
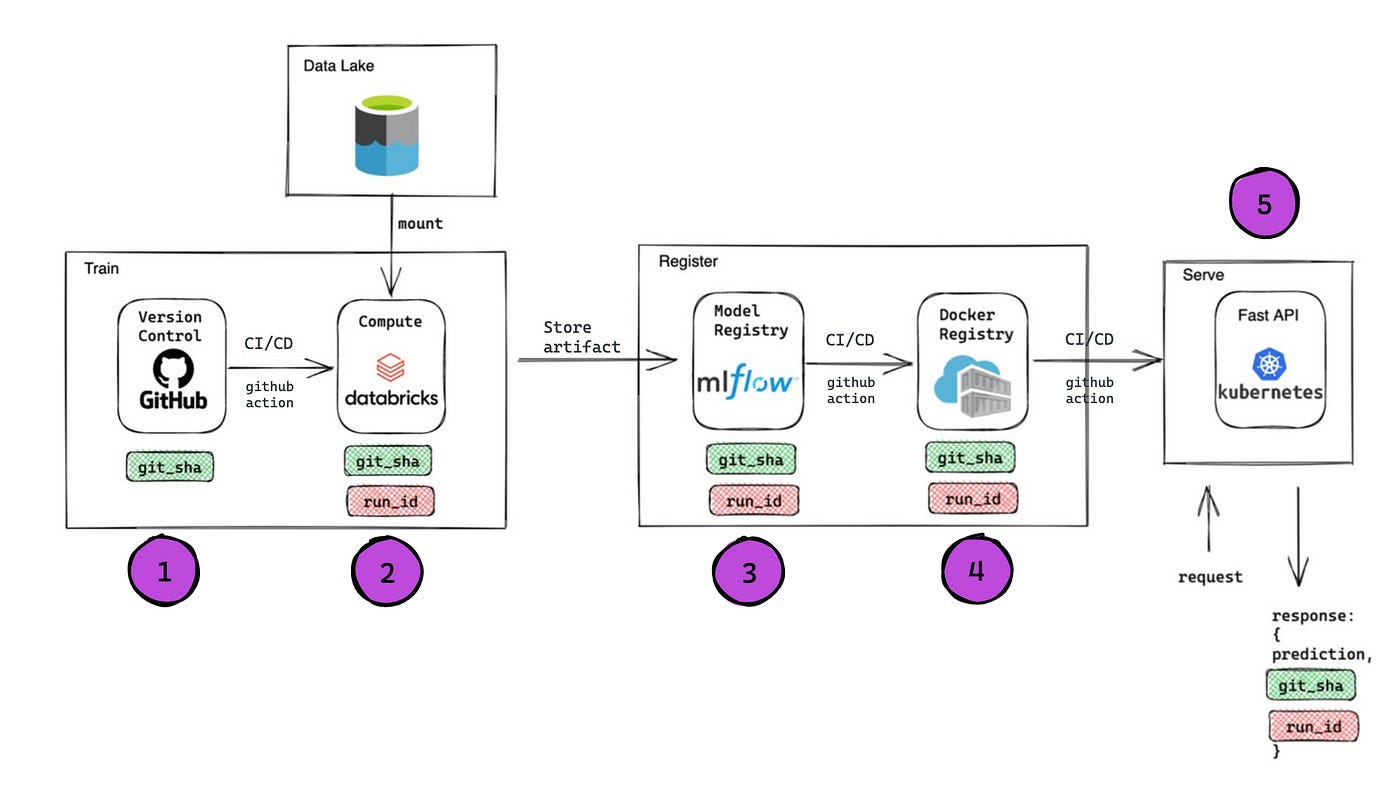
Step1: GIT_SHA allows us to track version of the code
At each release, in the GitHub action pipeline, we export GIT_SHA as an environment variable, use jinja2 to update Databricks job json definition so that it becomes available for python jobs running on Databricks. This indicates which version of code is used in that particular job.
We deploy training jobs to Databricks via json configuration using GitHub Actions.
# example of GitHub action
steps:
- name: Setup env vars
id: setup_env_vars
run: |
echo "GIT_SHA=${{ github.sha }}" >> $GITHUB_ENV
echo "DATABRICKS_TOKEN=${{ secrets.DATABRICKS_TOKEN }}" >> $GITHUB_ENV
echo "DATABRICKS_HOST=${{ secrets.DATABRICKS_HOST }}" >> $GITHUB_ENV# example of job cluster definition in Databricks job json
"job_clusters": [
{
"job_cluster_key": "recommender_cluster",
"new_cluster": {
"spark_version": "12.2.x-cpu-ml-scala2.12",
"node_type_id": "Standard_D4s_v5",
"spark_conf": {
"spark.speculation": true
},
"azure_attributes": {
"availability": "SPOT_WITH_FALLBACK_AZURE"
},
"autoscale": {
"min_workers": 2,
"max_workers": 4
},
"spark_env_vars": {
"DATABRICKS_HOST": "{{ DATABRICKS_HOST }}",
"GIT_SHA": "{{ GIT_SHA }}",
}
}
}
]Step2: Databricks run_id and job_id
Each Databricks job and job run has job_id and run_id as unique identifiers. run_id and job_id can be made available inside a python script that runs via Databricks job through the task parameter variable {{run_id}}.
It is also possible to retrieve run_id using dbutils. We do not use it since we want python script to be runnable locally too.
{{job_id}} : The unique identifier assigned to a job
{{run_id}} : The unique identifier assigned to a job run
{{parent_run_id}} : The unique identifier assigned to the run of a job with multiple tasks.
{{task_key}} : The unique name assigned to a task that’s part of a job with multiple tasks.
"spark_python_task": {
"python_file": "recommender/train_recommender.py",
"parameters": [
"--job_id",
"{{job_id}}",
"--run_id",
"{{parent_run_id}}"
]
}Example python code to catch run_id and job_id from Databricks job run:
import argparse
import os
def get_arguments():
parser = argparse.ArgumentParser(description=’reads default arguments’)
parser.add_argument('--run_id', metavar='run_id', type=str, help='Databricks run id')
parser.add_argument('--job_id', metavar='job_id', type=str, help='Databricks job id')
args = parser.parse_args()
return args.run_id, args.job_id
run_id, job_id = get_arguments()
git_sha = os.environ['GIT_SHA']
project_name = 'amazon-recommender'Step3: Register model in MLflow so that can be retrieved by specific run id
When registering models to mlflow model registry, we add the attributes GIT_SHA, DBR_RUN_ID, DBR_JOB_ID as tags.
import mlflow
mlflow.set_experiment(experiment_name='/Shared/Amazon_recommender')
with mlflow.start_run(run_name="amazon-recommender") as run:
recom_model = AmazonProductRecommender(spark_df=spark_df).train()
wrapped_model = AmazonProductRecommenderWrapper(recom_model)
mlflow_run_id = run.info.run_id
tags = {
"GIT_SHA": git_sha,
"MLFLOW_RUN_ID": mlflow_run_id,
"DBR_JOB_ID": job_id,
"DBR_RUN_ID": run_id,
}
mlflow.set_tags(tags)
mlflow.pyfunc.log_model("model", python_model=wrapped_model)
model_uri = f"runs:/{mlflow_run_id}/model"
mlflow.register_model(model_uri, project_name, tags=tags)The model registered with tags looks like this:
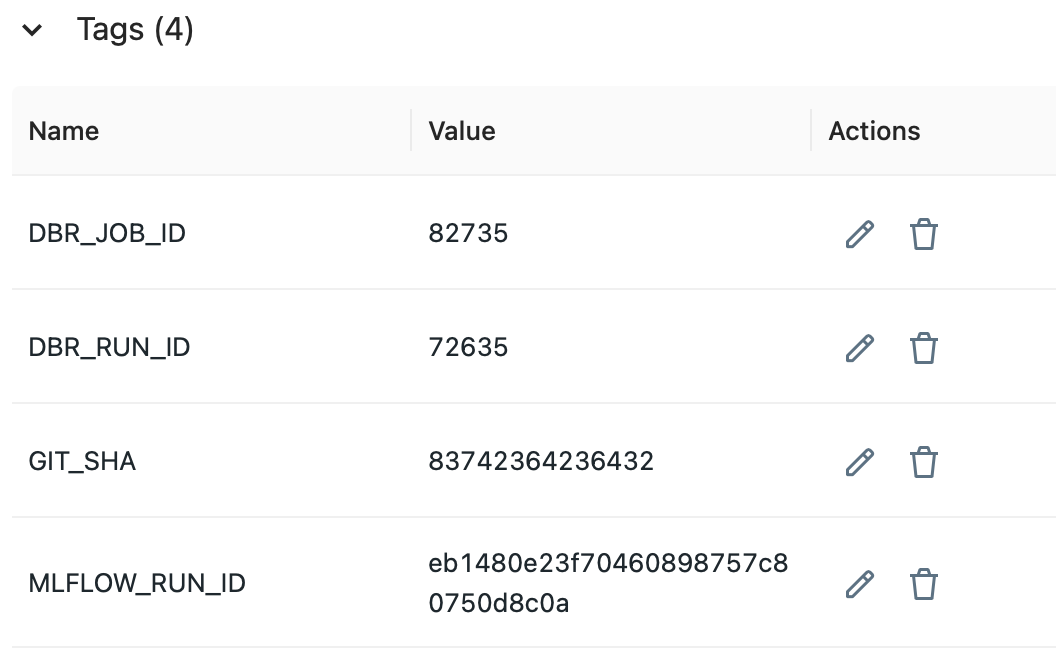
Step4: Embed model into docker image via run_id
Model can be downloaded from the MLflow registry by run id and copied to the docker image at docker build step.
Example code:
from mlflow.tracking.client import MlflowClient
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
client = MlflowClient()
model_version = client.search_model_versions(
f"name='{project_name}' and tag.DBR_RUN_ID = ‘{run_id}’
)[0].version
ModelsArtifactRepository(
f"models:/{project_name}/{model_version}"
).download_artifacts(artifact_path="", dst_path=download_path)Step5: Deploy API to Kubernetes with attributes
The attributes saved to the model registry are also included in the docker image as environment variables; git_sha, run_id. For full traceability, each response body is saved into the logging system with the attributes available in the environment git_sha, run_id.
Example code: git_sha and run_id are passed as environment variables via deployment manifest
apiVersion: apps/v1 kind: Deployment
metadata:
name: "amazon-recommender"
spec:
containers:
- name: amazon-recommender-api
image: <ACR_URL>/amazon-recommender:<GIT_SHA>-<RUN_ID>
env:
- name: git_sha
value: <GIT_SHA>
- name: run_id
value: <RUN_ID>Example code: Environment variables are then accessible in a FastAPI app
app = FastAPI()
@app.get("/predict/{query}")
def read_item (basket: List[str] = Query(None)):
return {
"recommended_items": model.predict(basket),
"run_id": os.environ["run_id"],
"git_sha": os.environ["git_sha"]
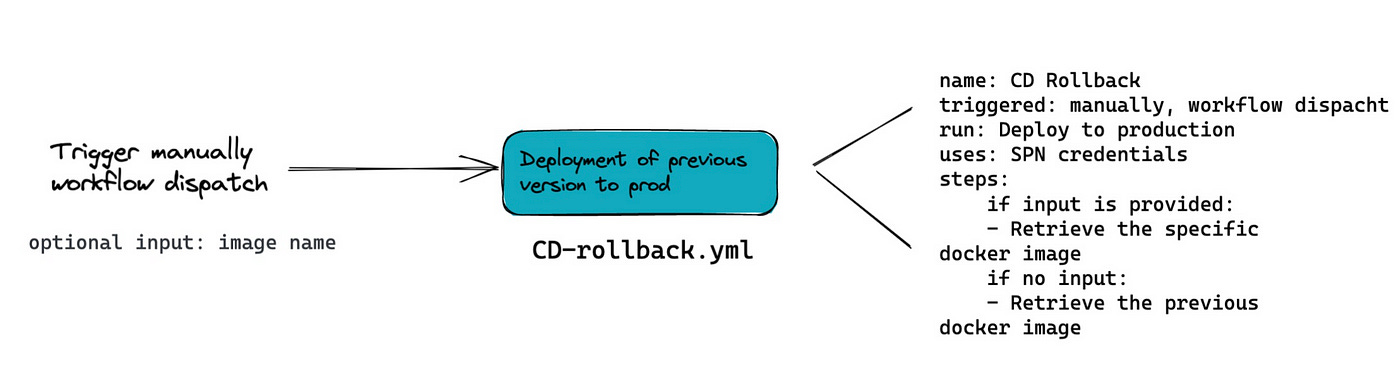
}Reproducibility: Roll-back
To re-deploy the previous version or a specific version for API deployment, we run a CD-rollback pipeline manually with a specific image name.
Each docker image saved to ACR (Azure Container Registry) is named with a unique identifier, which is Databricks run_id of corresponding training job run. If we would like to re-deploy a specific model, we manually trigger the deployment pipeline for roll-back (GitHub action) by providing the specific run_id. If there is no run_id provided, then it re-deploys the previous image.