


The advent of Polars is not surprising given the performance it delivers. Recently, it became also possible to use external engines for consuming data from Databricks Unity Catalog (UC), which means we can read data directly into a Polars dataframe by utilizing pyarrow and Deltalake.
This can be particularly useful for machine learning projects, which utilize libraries like scikit-learn that expect Pandas or Polars dataframe as an input. If the source data is stored as a delta table in Unity Catalog, a standard approach of first creating a pyspark dataframe and then transforming it into a Polars or Pandas dataframe can be very inefficient. Instead, we would like to read data from Unity Catalog without going through pyspark.

In this article, we show how to achieve that. We also challenge the idea of using pyspark or spark SQL for data transformation (which is common for data preprocessing pipelines), showing that using Polars can help to achieve serious speedup and cost savings for certain data sizes.
Benchmark & requirements
For the benchmark we used the industry standard TPC-H benchmark: https://www.tpc.org/tpch/. The functions are the ones as used again from the repository from Polars: https://github.com/pola-rs/polars-benchmark.
All the code for the article can be found in the repository. For your convenience, we made all the data available via a shared folder and prepared the scripts to dump the files in a Volume, and create the external tables with the feature of deleteVectors turned off. You can run the notebooks yourself to experience the difference in performance with minimal effort.
These are the steps:
Clone the repository into your Databricks workspace using the Git folder feature. It is a public repository, so you do not have to authenticate
Update project_config file to use your preferred catalog and schema
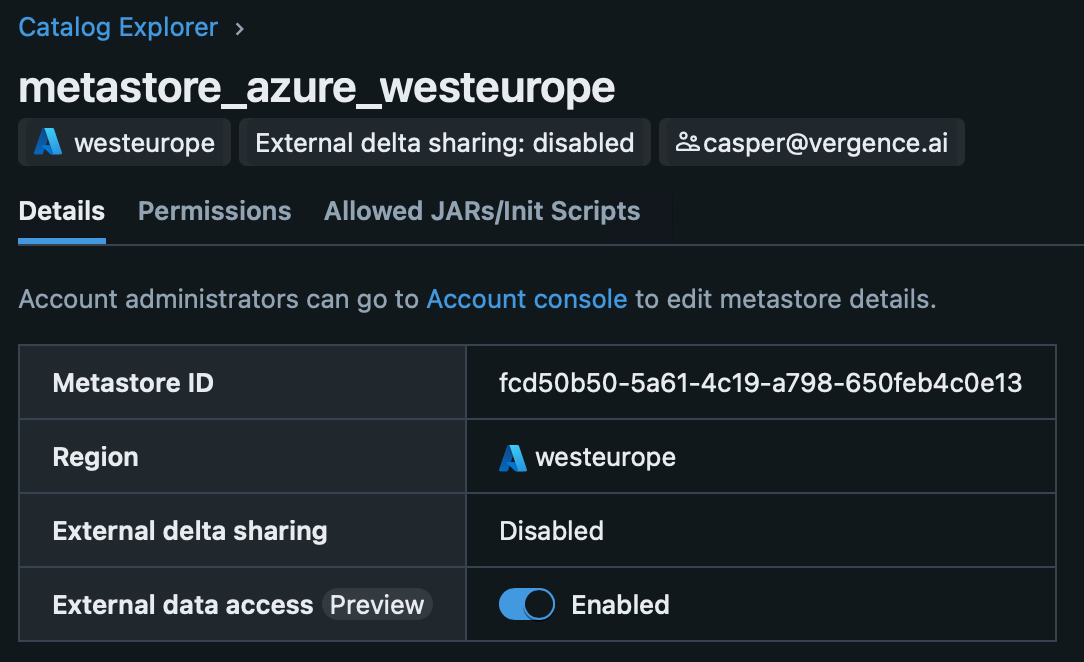
Toggle ‘External Data Access’ via the Metastore Toggle in the Catalog Explorer (Figure 1).
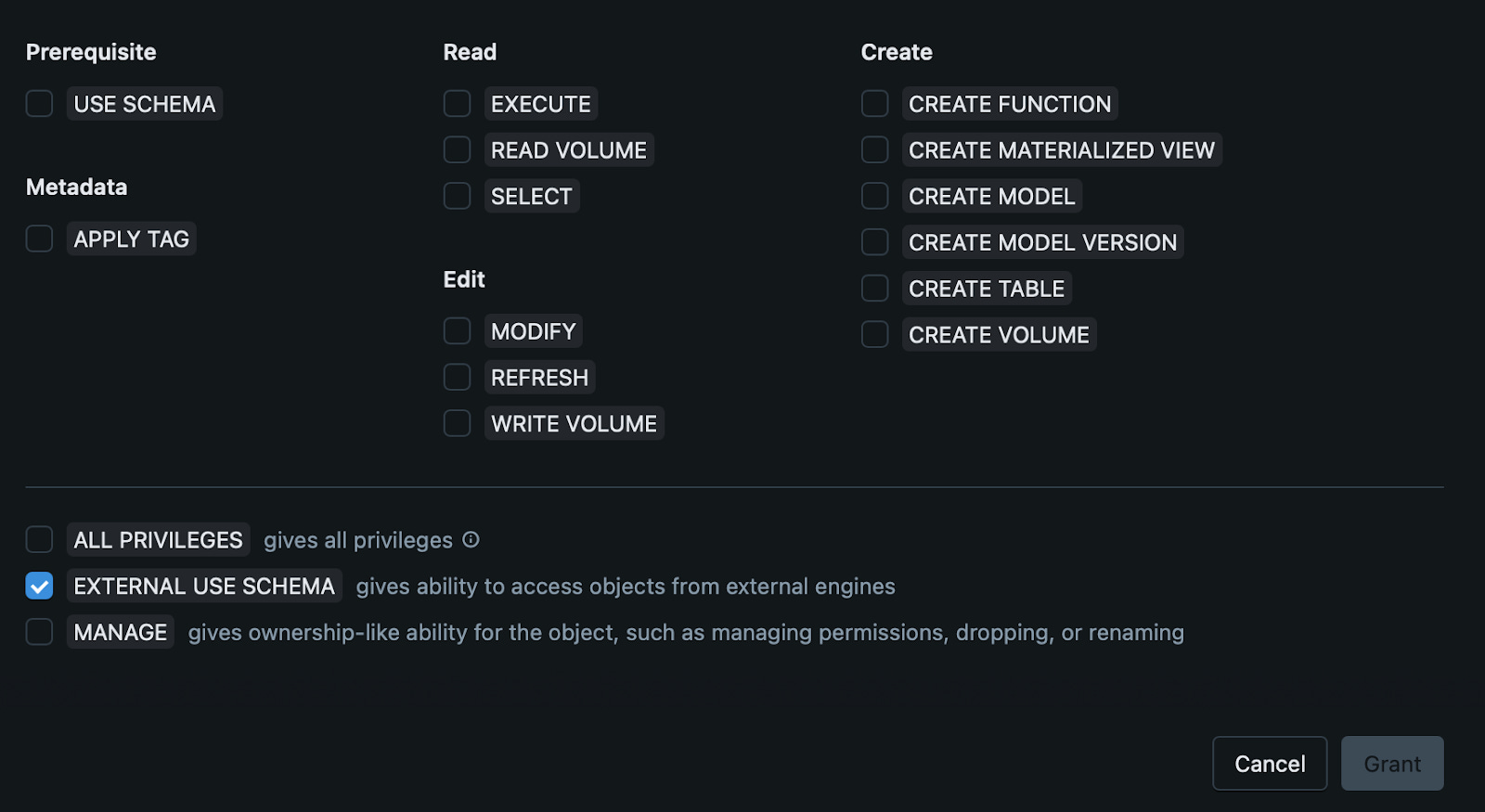
Grant the EXTERNAL_USE_SCHEMA privilege to your user. This will be exposed once the toggle above has switched. Note: ALL_PRIVILEGES does not include the EXTERNAL_USE_SCHEMA privilege (Figure 2).
Run notebooks/init_benchmark_uc.py script (you need to have permissions to create schemas and volumes) to download the data from the shared folder and create delta tables
Execute notebooks/run_notebooks.py using Serveless cluster vs classic compute.
To read data from Unity Catalog, we will use the mechanism of credential vending. It works using short-living tokens and entirely bypasses the dependency of Spark. In the notebook, we use a personal access token that we retrieve using dbutils. For production, you need to create a service principal and store its token in a secret scope.
Findings
As expected, on smaller datasets (x1, x3 scale) Polars runs faster than PySpark (Figure 3). Up to 2.5 times as fast (as measured by rerunning the TPC-H benchmark as defined in the repo for the Polars benchmark).
The problem is, it doesn’t scale well (serverless supports max 32 gb RAM). With the demonstrated approach you load all the data directly into the local RAM and execute. There are ways to compute out-of-core, but at the time of writing not possible with reliability: the short-living token connection with Unity Catalog does not seem very reliable. For some reason the load data command keeps hanging without timing out, you really need to reset the entire instance for it to work again. When running the code locally, this issue does not seem to be present.
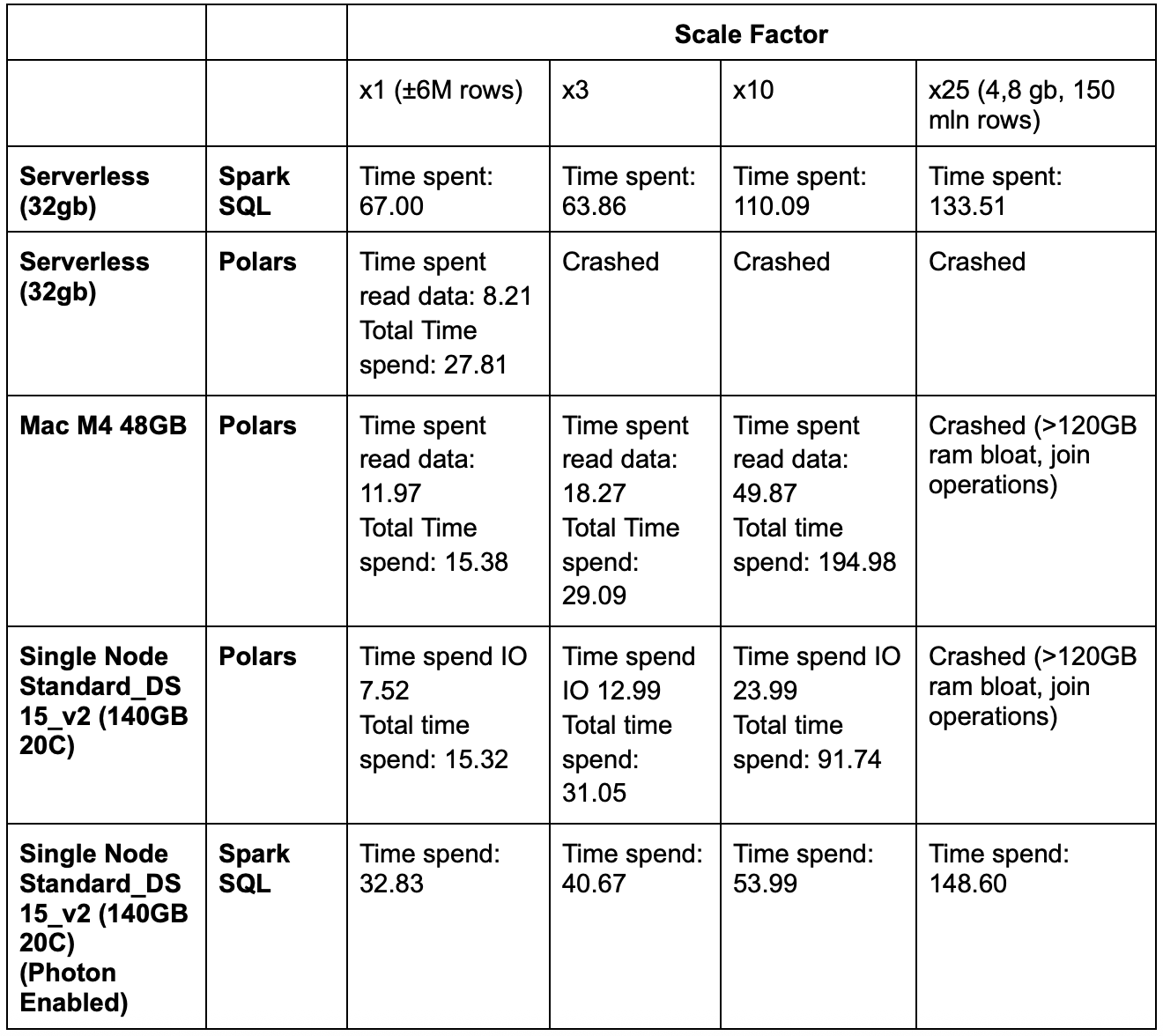
When it comes to the costs, on x1 scale on serverless (32 gb), using polars is at least 15x cheaper than running the same workload using Spark (total cost is 0,183 dollar vs 3,267 dollar, for 15 runs). Figure 4 shows the distribution of individual runs. On a larger scale (x10), using Spark SQL would be more cost effective.

Downsides
Reading from Unity Catalog. Currently (20-05-2025) Polars doesn’t seem to support it to read directly from Unity Catalog: an obscure error is raised that mentions the URL, despite trying various methods. However, what did work is to read the table via the library deltalake. This can be used to expose an arrow dataset, which subsequently can be loaded into Polars. Probably in the near future direct read can be supported.
Writing to Unity Catalog. This seems not yet possible as both the Deltalake and Polars libraries raise an error when trying. However, it can be done by writing directly to the storage as delta table, and creating an external table referring to that data.
Breaking the lineage. Databricks' Unity Catalog captures post-facto lineage at runtime. You need to have executed code, for it to be able to pick up what the lineage between data objects was. However, this only works for pyspark. Databricks is working on the Bring Your Own Lineage feature, which will allow users to update the lineage themselves. This would solve, with effort, the downside of running an external engine: losing the lineage. For machine learning projects, we could tag MLflow experiment runs, passing information about the table location, and the version of delta table.
Conclusions
Reading data directly from a delta table without using Spark is a great idea if you do not need Spark for your workload (for example, for a machine learning workflow). It is possible to run the code anywhere: on your local PC, standard cluster, or serverless.
For data preprocessing, it may be beneficial to use polars too (for smaller datasets). You can save quite some costs – at a cost. The cost being that you lose the sweet features that the Spark on Databricks provides; mostly the lineage, but also that not all features of the tables are supported and need to be turned off. What you save can be quite impressive, though: running a (small) load on Serverless, you can in the smallest instance reach a speed up of 3x on Serverless in comparison with PySpark, or a 10x speedup when running locally on a Macbook M4 Pro.
 | A guest post by
|
Makes me want to try the same thing with Daft