

Databricks recently introduced Free Edition, which opened the door for us to create a free hands-on course on MLOps with Databricks.
This article is part of that course series, where we walk through the tools, patterns, and best practices for building and deploying machine learning workflows on Databricks.
In this lecture, we’ll focus on how to automate and the entire ML workflow using DAB. You can also follow along with the full walkthrough on the Marvelous MLOps YouTube channel:
All code covered in this repository is available here.
Why Databricks Asset Bundles?
When deploying resources and their dependencies on Databricks, you have a few options:
Terraform: Full infrastructure-as-code control, but can be complex.
Databricks APIs: Flexible, but requires custom scripting.
Databricks Asset Bundles (DAB): The recommended, declarative, YAML-based approach.
DAB offers a balance between simplicity and power. Under the hood, it leverages Terraform, so you get all the benefits of infrastructure-as-code, without having to manage raw Terraform code yourself. This is ideal for teams looking to standardize and automate job deployments in a scalable, maintainable way.
What is DAB?
Databricks Asset Bundle (DAB) is the way to package your code, jobs, configuration, and dependencies together in a structured, version-controlled format. With DAB, you define jobs, notebooks, models, and their dependencies using YAML files.
Key features:
Declarative YAML configuration: Define everything in one place.
Multi-environment support: Easily target dev, staging, prod, etc.
CI/CD friendly: Fits naturally into automated pipelines.
Version-controlled: All changes are tracked in your repo.
What is a Lekeflow job?
Lakeflow Jobs (previously Databricks workflows) provide the execution and orchestration layer. Workflows let you run tasks (notebooks, scripts, SQL) on a schedule or in response to events, with support for dependencies, retries, parameter passing, and alerts.
Machine learning pipeline
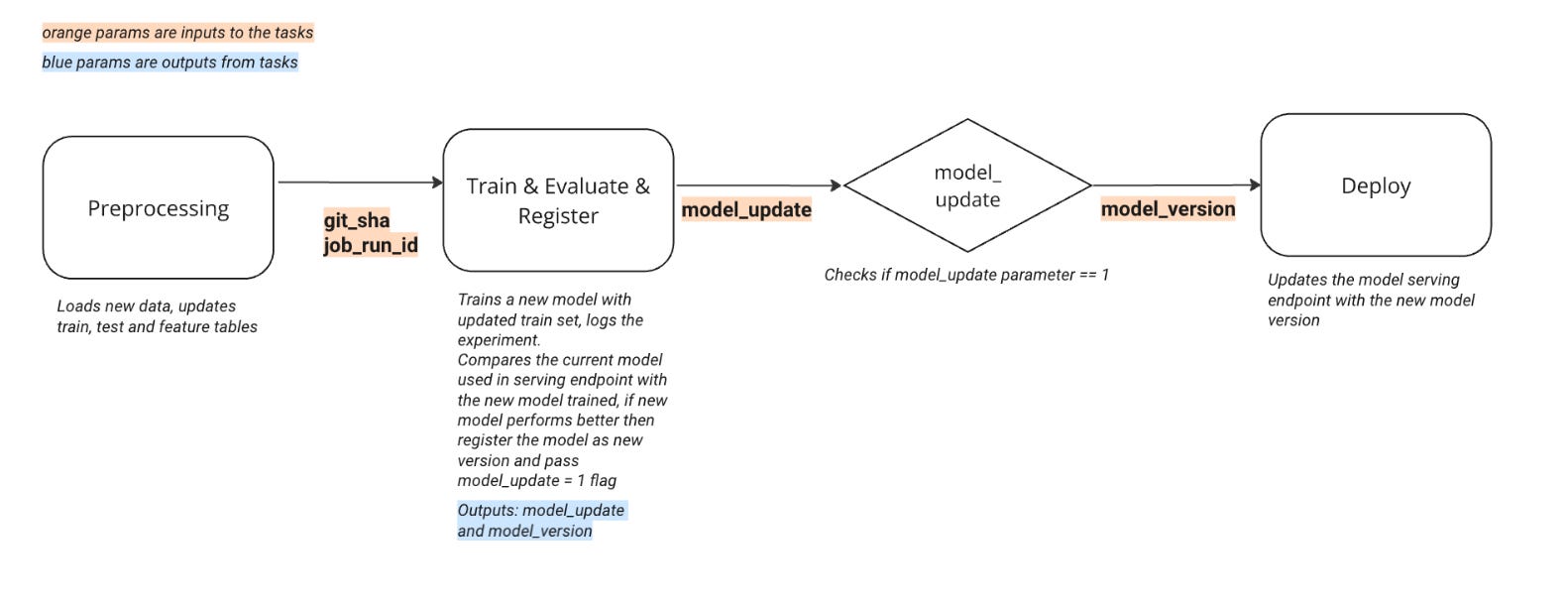
Here’s the workflow we’ll create with DAB:
Preprocessing. Runs a data processing script scripts/process_data.py.
Train & Evaluate. Trains and evaluates the model using scripts/train_register_custom_model.py.
Model Update. Conditional step: if the new model is better, release a flag and register it.
Deployment. Deploy the registered model by creating or updating a serving endpoint using scripts/deploy_model.py.
The scripts we are running in each step can be found in the scripts folder in our repo. Parameters are passed between steps, and are explicitly defined in our databricks.yml file.
databricks.yml file
The bundle configuration is defined in the databricks.yml. The minimal configuration only contains the bundle name and the target. Let’s look at the databricks.yml file from our project:
bundle:
name: marvel-characters
include:
- resources/*
artifacts:
default:
type: whl
build: uv build
path: .
variables:
git_sha:
description: git_sha
default: abcd
branch:
description: branch
default: main
schedule_pause_status:
description: schedule pause status
default: PAUSED
targets:
dev:
default: true
mode: development
workspace:
host: <your host>
root_path: /Workspace/Users/${workspace.current_user.userName}/.bundle/${bundle.target}/${bundle.name}
profile: marvelous
variables:
schedule_pause_status: PAUSED
acc:
presets:
name_prefix: 'acc_'
workspace:
host: <your host>
root_path: /Shared/.bundle/${bundle.target}/${bundle.name}
profile: marvelous
variables:
schedule_pause_status: PAUSED
prd:
mode: production
workspace:
host: <your host>
root_path: /Shared/.bundle/${bundle.target}/${bundle.name}
profile: marvelous
variables:
schedule_pause_status: PAUSED # normally UNPAUSEDThe databricks.yml file here does not contain any resources. All the resources are defined under the resource folder as separate .yml files. The resource configurations are included in the deployment thanks to the include section in the main configuration file.
The artifacts section defines how the code is packaged. The packaged code is referenced in the resources.
The variables section defines shared variables (git SHA, branch, schedule status), which can be defined per target or passed to the deployment at the deploy step.
The targets section defines deployment targets, which refer to separate environments (dev, acc, prd), each with its own settings.
Machine learning pipeline: model_deployment.yml
The resources/model_deployment.yml file defines the actual ML workflow as a Databricks job, with tasks and dependencies.
The file contains one job with a schedule that will be paused based on the variable value schedule_pause_status. We want to schedule the job in production, but pause it for acceptance target (which does not have development mode, hence will not be paused by default).
The job will run using serverless environment 3, which we discussed earlier in lecture 2.
resources:
jobs:
deployment:
name: ${bundle.name}-workflow
schedule:
quartz_cron_expression: "0 0 6 ? * MON"
timezone_id: "Europe/Amsterdam"
pause_status: ${var.schedule_pause_status}
tags:
project_name: "marvel-characters"
environments:
- environment_key: default
spec:
client: "3"
dependencies:
- ../dist/*.whl
tasks:
- task_key: "preprocessing"
environment_key: default
spark_python_task:
python_file: "../scripts/process_data.py"
parameters:
- "--root_path"
- "${workspace.root_path}"
- "--env"
- "${bundle.target}"
- task_key: "train_model"
environment_key: default
depends_on:
- task_key: "preprocessing"
spark_python_task:
python_file: "../scripts/train_register_custom_model.py"
parameters:
- "--root_path"
- "${workspace.root_path}"
- "--env"
- "${bundle.target}"
- "--git_sha"
- "${var.git_sha}"
- "--job_run_id"
- "{{job.run_id}}"
- "--branch"
- "${var.branch}"
- task_key: model_updated
condition_task:
op: "EQUAL_TO"
left: "{{tasks.train_model.values.model_updated}}"
right: "1"
depends_on:
- task_key: "train_model"
- task_key: "deploy_model"
environment_key: default
depends_on:
- task_key: "model_updated"
outcome: "true"
spark_python_task:
python_file: "../scripts/deploy_model.py"
parameters:
- "--root_path"
- "${workspace.root_path}"
- "--env"
- "${bundle.target}"The job consists of tasks: preprocessing, training, model update check, deployment. We pass parameters between the tasks using DABs, and also pass specific Python parameters to the tasks, such as the job run id, and git_sha, which allows us to tag MLflow runs and registered models with the actual code version.
Let’s take a closer look at each of the tasks.
Preprocessing Script: scripts/process_data.py
The preprocessing script handles data loading and preprocessing, similar to what we have done in lecture 2. We are using DataProcessor class from our custom package, which can be found under src folder.
import argparse
import yaml
from loguru import logger
from pyspark.sql import SparkSession
import pandas as pd
from marvel_characters.config import ProjectConfig
from marvel_characters.data_processor import DataProcessor
parser = argparse.ArgumentParser()
parser.add_argument(
"--root_path",
action="store",
default=None,
type=str,
required=True,
)
parser.add_argument(
"--env",
action="store",
default=None,
type=str,
required=True,
)
args = parser.parse_args()
config_path = f"{args.root_path}/files/project_config_marvel.yml"
config = ProjectConfig.from_yaml(config_path=config_path, env=args.env)
logger.info("Configuration loaded:")
logger.info(yaml.dump(config, default_flow_style=False))
# Load the Marvel characters dataset
spark = SparkSession.builder.getOrCreate()
# Example: Adjust the path and loading logic as per your Marvel dataset location
filepath = f"{args.root_path}/files/data/marvel_characters_dataset.csv"
# Load the data
df = pd.read_csv(filepath)
# If you have Marvel-specific synthetic/test data generation, use them here.
# Otherwise, just use the loaded Marvel dataset as is.
logger.info("Marvel data loaded for processing.")
# Initialize DataProcessor
data_processor = DataProcessor(df, config, spark)
# Preprocess the data
data_processor.preprocess()
# Split the data
X_train, X_test = data_processor.split_data()
logger.info("Training set shape: %s", X_train.shape)
logger.info("Test set shape: %s", X_test.shape)
# Save to catalog
logger.info("Saving data to catalog")
data_processor.save_to_catalog(X_train, X_test)Training & Registration Script: scripts/train_register_custom_model.py
This script trains, evaluates, and registers the model, if the model is improved. We are using custom model class which we created in lecture 4.
import argparse
import mlflow
from loguru import logger
from pyspark.dbutils import DBUtils
from pyspark.sql import SparkSession
from importlib.metadata import version
from marvel_characters.config import ProjectConfig, Tags
from marvel_characters.models.basic_model import BasicModel
from marvel_characters.models.custom_model import MarvelModelWrapper
parser = argparse.ArgumentParser()
parser.add_argument(
"--root_path",
action="store",
default=None,
type=str,
required=True,
)
parser.add_argument(
"--env",
action="store",
default=None,
type=str,
required=True,
)
parser.add_argument("--git_sha", type=str, required=True, help="git sha of the commit")
parser.add_argument("--job_run_id", type=str, required=True, help="run id of the run of the databricks job")
parser.add_argument("--branch", type=str, required=True, help="branch of the project")
args = parser.parse_args()
root_path = args.root_path
config_path = f"{root_path}/files/project_config_marvel.yml"
config = ProjectConfig.from_yaml(config_path=config_path, env=args.env)
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
tags_dict = {"git_sha": args.git_sha, "branch": args.branch, "job_run_id": args.job_run_id}
tags = Tags(**tags_dict)
# Initialize Marvel custom model
basic_model = BasicModel(config=config, tags=tags, spark=spark)
logger.info("Marvel BasicModel initialized.")
# Load Marvel data
basic_model.load_data()
logger.info("Marvel data loaded.")
# Prepare features
basic_model.prepare_features()
# Train the Marvel model
basic_model.train()
logger.info("Marvel model training completed.")
# Train the Marvel model
basic_model.log_model()
# Evaluate Marvel model
model_improved = basic_model.model_improved()
logger.info("Marvel model evaluation completed, model improved: %s", model_improved)
if model_improved:
# Register the model
basic_model.register_model()
marvel_characters_v = version("marvel_characters")
pyfunc_model_name = f"{config.catalog_name}.{config.schema_name}.marvel_character_model_custom"
code_paths=[f"{root_path}/artifacts/.internal/marvel_characters-{marvel_characters_v}-py3-none-any.whl"]
wrapper = MarvelModelWrapper()
latest_version = wrapper.log_register_model(wrapped_model_uri=f"{basic_model.model_info.model_uri}",
pyfunc_model_name=pyfunc_model_name,
experiment_name=config.experiment_name_custom,
input_example=basic_model.X_test[0:1],
tags=tags,
code_paths=code_paths)
logger.info("New model registered with version:", latest_version)
dbutils.jobs.taskValues.set(key="model_version", value=latest_version)
dbutils.jobs.taskValues.set(key="model_updated", value=1)
else:
dbutils.jobs.taskValues.set(key="model_updated", value=0)Deployment Script: scripts/deploy_model.py
The deployment script deploys the latest registered model to a serving endpoint. We covered the logics in lecture 6.
import argparse
from loguru import logger
from pyspark.dbutils import DBUtils
from pyspark.sql import SparkSession
from marvel_characters.config import ProjectConfig
from marvel_characters.serving.model_serving import ModelServing
parser = argparse.ArgumentParser()
parser.add_argument(
"--root_path",
action="store",
default=None,
type=str,
required=True,
)
parser.add_argument(
"--env",
action="store",
default=None,
type=str,
required=True,
)
args = parser.parse_args()
config_path = f"{args.root_path}/files/project_config_marvel.yml"
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
model_version = dbutils.jobs.taskValues.get(taskKey="train_model", key="model_version")
# Load project config
config = ProjectConfig.from_yaml(config_path=config_path, env=args.env)
logger.info("Loaded config file.")
catalog_name = config.catalog_name
schema_name = config.schema_name
endpoint_name = f"marvel-characters-model-serving-{args.env}"
endpoint_name = "marvel-character-model-serving"
# Initialize Marvel Model Serving Manager
model_serving = ModelServing(
model_name=f"{catalog_name}.{schema_name}.marvel_character_model_custom",
endpoint_name=endpoint_name
)
# Deploy the Marvel model serving endpoint
model_serving.deploy_or_update_serving_endpoint(version=model_version)
logger.info("Started deployment/update of the Marvel serving endpoint.")Running and Managing Bundles
We use Databricks CLI commands to validate, deploy and run our workflow.
databricks bundle validate — validate your bundle
databricks bundle deploy — deploys your bundle
databricks bundle run — run the job
databricks bundle destroy — Tear down resources
Once we deploy our bundle, we see our workflow created in the target workspace.
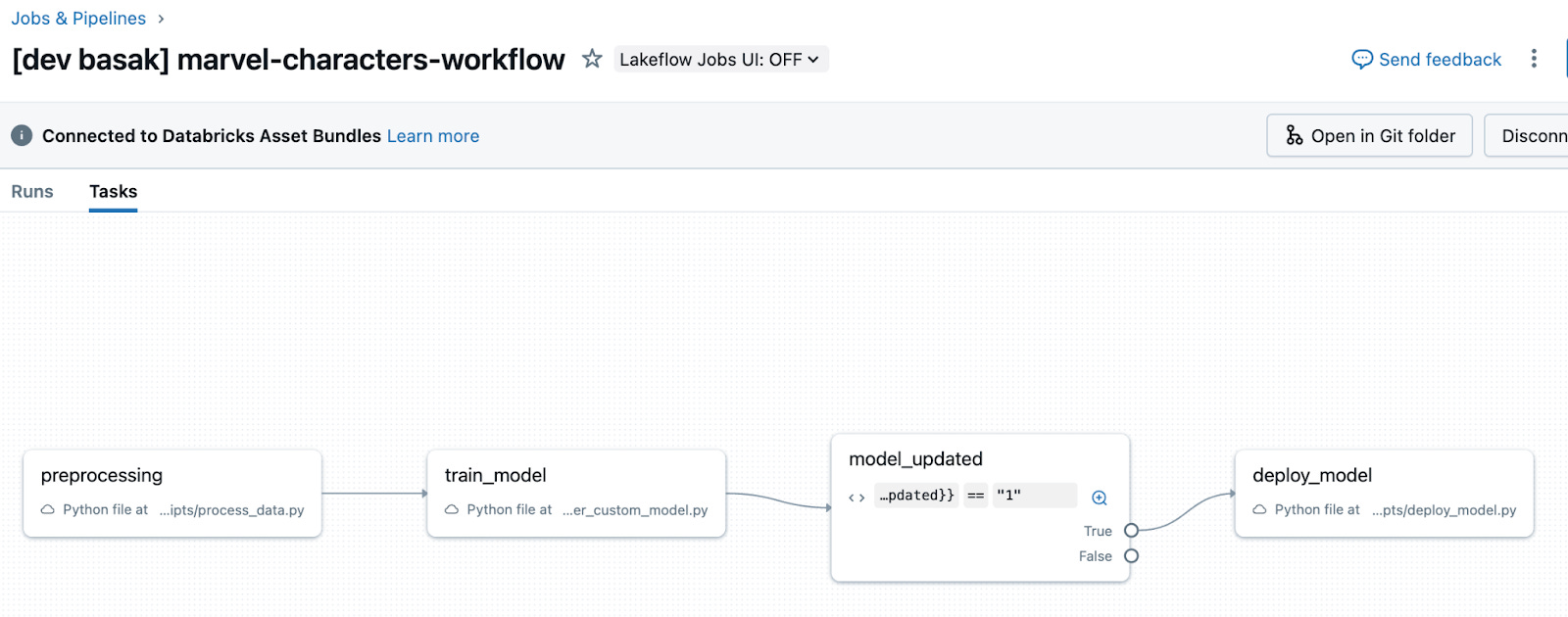
Conclusion
With Databricks Asset Bundles, we can package all logic, dependencies, and configurations together, define robust multi‑step ML workflows, and version and automate deployments across environments. This enables true reproducibility and aligns with CI/CD best practices, making deployments consistent and reliable.
In the next lecture, we will explore how to deploy a bundle through a CI/CD pipeline to fully automate the path from development to production.